Case study: The unexpected impact of blocking GoogleOther on SEO performance

What happened
A client’s IT team blocked GoogleOther by IP to relieve an overloaded translation database. Within days, Search Console started reporting server connectivity errors, on some domains up to 40% of requests failing.
The cause was not a secret link between GoogleOther and Search. It was simpler and more useful to know: GoogleOther runs on the same IP ranges as Googlebot. An IP-level block aimed at one crawler caught the other. Google’s own documentation states that GoogleOther has no effect on Search indexing or rankings, and that held true here. The damage came entirely from how the block was implemented, not from GoogleOther itself.
We removed the firewall rule, disallowed GoogleOther in robots.txt, and the errors cleared. This post walks through the whole incident and the reasoning behind the fix.
The trigger: a translation database under load
In January 2025, the client’s team noticed their translations database taking unusual strain.
Their logs pointed at Google. Bot traces jumped sharply starting January 23, 2025. In Azure monitoring, a “trace” is a logged event tracking how a specific bot interacts with the application, used for performance monitoring and debugging.
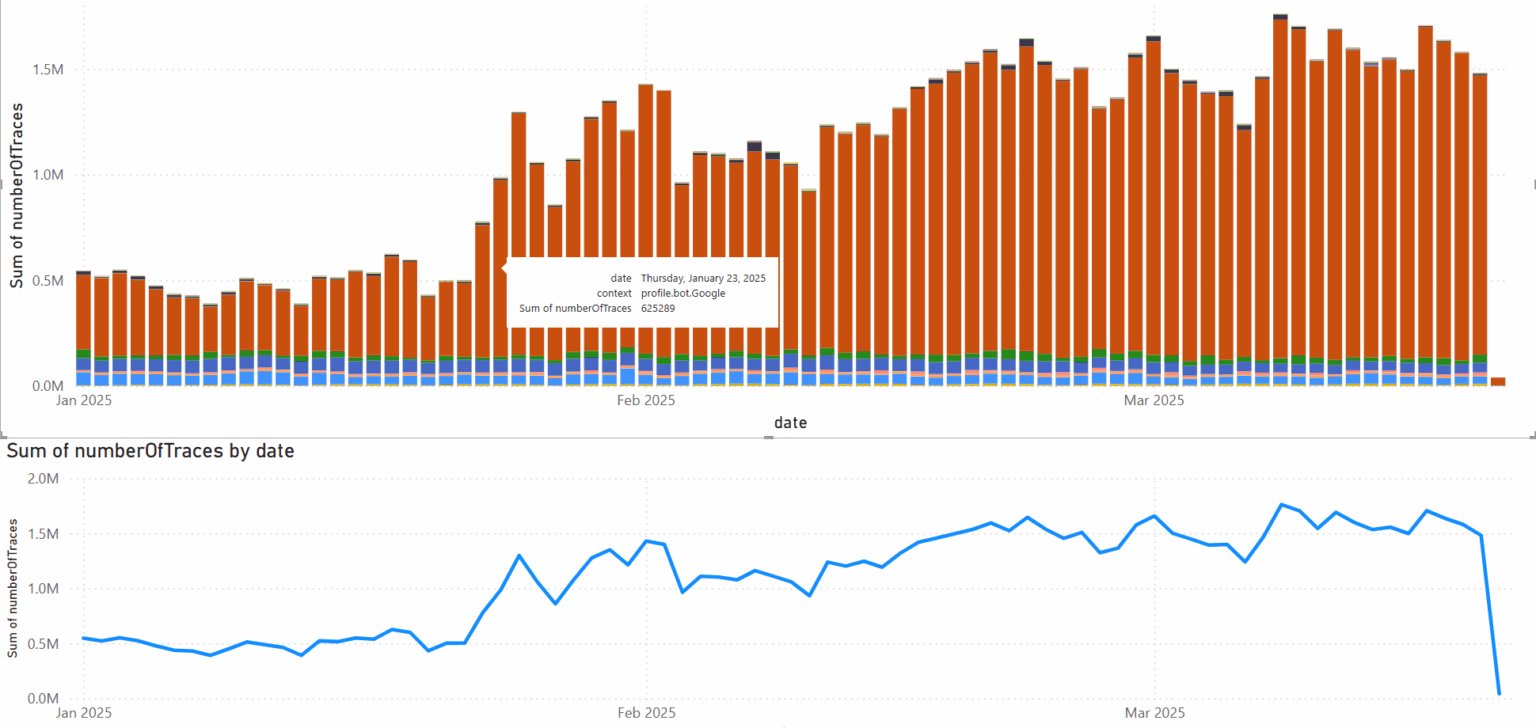
The source was GoogleOther, a crawler Google introduced in April 2023. Google describes it as a generic crawler that various product teams can use to fetch publicly accessible content, for example one-off crawls for internal research and development. Gary Illyes explained on launch that GoogleOther exists to take some strain off Googlebot, so that Googlebot’s crawl jobs stay dedicated to building the Search index. Before GoogleOther existed, regular Googlebot handled these non-Search crawls.
Working from Google’s framing of GoogleOther as a separate, non-Search crawler, the IT team decided the safe move was to block it. They wrote an Azure Front Door WAF rule to do it by IP.
The consequence: Search Console connectivity errors
Blocking GoogleOther by IP caused a spike in Search Console connectivity errors.
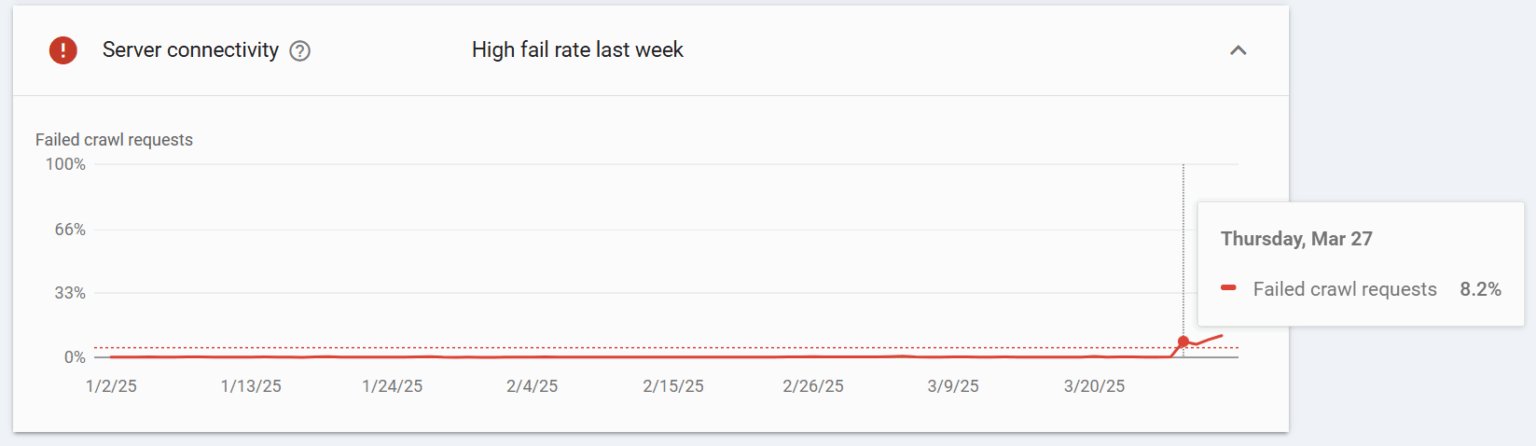
The screenshot above is one of the least affected domains. On others, up to 40% of server requests were failing. That raised the question worth answering: if blocking a supposedly non-Search crawler damages Search Console, what is actually connected to what?
Why the block hit Search: shared IP ranges
GoogleOther and Googlebot crawl from the same IP ranges. Block one by IP and you block the other.
This is documented by Google, but it is easy to miss. GoogleOther uses the same infrastructure as Googlebot: same host-load limits, same HTTP protocol handling, same IP ranges. Only the user-agent token differs. Illyes described it as basically Googlebot under a different name.
Our logs confirmed it directly:
- The IP most often caught by the client’s “BlockGoogleOther” rule was 66.249.70.66, blocked 123,384 times in a single week.
- That same IP served over 10,000 regular Googlebot requests in the same week.
So the WAF rule was never blocking only GoogleOther. It was blocking a shared Google crawl IP, and Googlebot was collateral damage. That is what Search Console was reporting.
This shared-range behavior has been discussed in the WebmasterWorld forum and other SEO communities. SEOs who work in logs tend to know it. IT teams almost never do, because it lives in crawler documentation they have no reason to read.
The fix: robots.txt, not a firewall
The correct way to limit GoogleOther is robots.txt, because GoogleOther obeys robots.txt and uses its own user-agent token. A robots.txt rule targets GoogleOther specifically and leaves Googlebot untouched.
We did two things:
- Removed the Azure Front Door WAF rule blocking GoogleOther by IP.
- Added this to robots.txt:
User-agent: GoogleOther
Disallow: /Results after the fix
Switching to robots.txt resolved the incident cleanly.
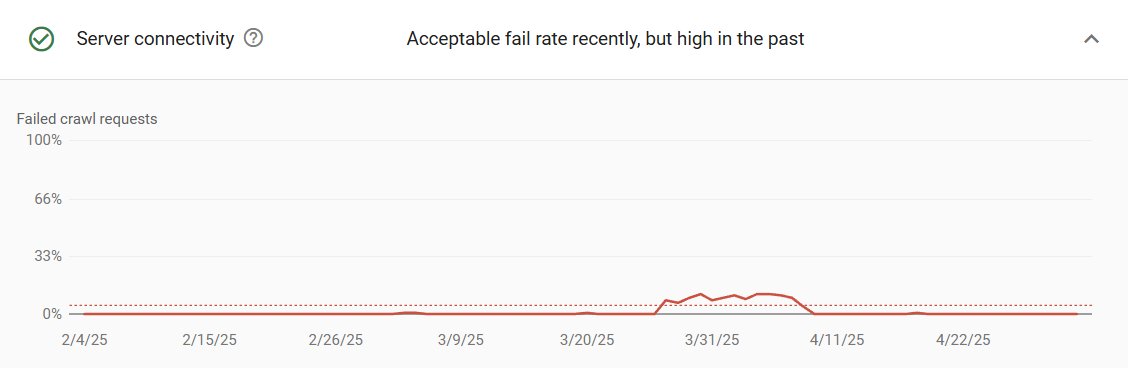
- Search Console connectivity errors returned to normal levels.
- Site performance stabilized, with server resource usage back to 3-4 instances.
- GoogleOther stopped hammering the translation database.
- Rankings and indexing were never affected.
Lessons learned
Google’s “separate crawler” framing hides an operational trap. GoogleOther is a distinct crawler with its own user agent, but it shares Googlebot’s IP ranges. Treating “separate crawler” as “separate everything” is how this incident started.
IP blocking is a blunt instrument for Google crawlers. Block one Google IP and you can take out Googlebot without realizing it. The user agent is the only reliable way to tell these crawlers apart, and firewalls that match on IP cannot see it.
Robots.txt is the right tool for GoogleOther. It respects robots.txt precisely and honors its own user-agent token, so you can limit it without touching Search.
Watch the Search Console crawl report after any technical change. It surfaced this problem fast and kept a database fix from turning into an SEO incident.
What this means for your team
IT teams reach for firewall rules to shed unwanted traffic, which is reasonable server management. For Google crawlers, it backfires, because an IP block cannot distinguish GoogleOther from Googlebot and robots.txt is rarely the first tool a security-focused team thinks of.
The lesson is not that GoogleOther secretly affects Search. It does not. The lesson is that a crawler decision made without SEO input turned into failed requests and Search Console errors. Get involved early in any technical decision that touches crawler access, before the firewall rule ships.